Introduction
The Financial Entity Identification and Information Integration (FEIII) challenge series aims to provide interesting datasets to researchers at the intersection of finance and big data. These datasets have sufficient data for exploration, but are left noisy and incomplete as they are found "in the wild". Each year we provide a specific evaluation task but we also strongly encourage participants to define tasks that match their research interests.
In year one, we posed an "identifier alignment" challenge: given four databases of financial entities from four different sources, participants needed to find the entities in common across the databases.
For year two, we are continuing with the theme of identifying and understanding the relationships among financial entities and the roles that they play in financial contracts as represented in documents and databases. The year two dataset consists of 10-K and 10-Q filings, and the task is to identify sentences in the filings that provide evidence for a specific relationship between the filing financial entity and another mentioned financial entity.
Data
The 2017 challenge data is here.
The seed dataset is drawn from the filings of 25+ holding companies with assets exceeding US$10Billion (HC>$10B financial entities) that have provided a resolution plan (Living Will). Using custom extractors developed by a team from the University of Maryland which leverage IBM System T tools, we have extracted the following triples from 10-K and 10-Q filings:
- Financial Entity Reference: The text string containing the company name of the Mentioned company.
- Role keyword(s): A relationship between the mentioned company and the Filing company.
- The contextual text around this reference and relationship that gives evidence of the relationship.
Scored Task
The scored challenge task this year is triple ranking: Rank the triples (within each role and within each filing financial entity) such that the triples with the context that best supports that role assignment and contains (financially) relevant knowledge are at the top of the ranking.
This task operationalizes the following scenario. Given a 10-K filing, an analyst asks, does Company Y, mentioned in this filing, play the role R with respect to filing Company X? Rather than simply answering "yes" or "no", a system responds by providing all the mentions of Company Y in Company X's 10-K filing, with context sentences. These triples are then in ordered by the likelihood that the context accurately defines the relationship or role R between X and Y.
The triple extraction was automated. Sometimes the roles do not correctly assign or explain the relationship between the filing financial entity and the mentioned entity. Some sentences are boilerplate. On the other hand, relevant context sentences correctly describe the relationship between the filing and mentioned financial entity. Very relevant context sentences also contain specific financially relevant knowledge. We asked a panel of experts to label training data triples as being (very) relevant, neutral or irrelevant.
Result
Participants in this task should write their systems to take the given CSV-formatted spreadsheets as input, and to output a new CSV file with an additional column. The input files have the fields (mentioned company, role keyword, context). The output files should add a column "score" that indicates the ranking score of that triple in supporting the role keyword. Participants should also sort the CSV file by role and descending score, but this is not strictly necessary as long as the scores are provided for each triple. Scores should be numbers between 0 and 1 inclusive, where 1 indicates the highest level of confidence, score, probability, or likelihood that the context supports an assertion of that role, and 0 indicates the lowest.
Scoring
We have asked domain experts to label whether each context supports the role assertion in each triple. This lets us view each participant output ranking as a list of correct and incorrect triples for each role. The score for an output ranking as the normalized discounted cumulative gain (NDCG), a measure frequently used by search engine companies, as follows. The output ranking gets one point of gain for each correct answer, discounted by the logarithm of the position in the ranking:
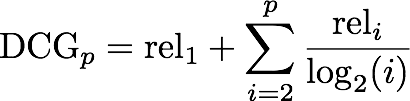
Non-scored tasks
We can consider the dataset and the scored challenge tasks as a building block of a more sophisticated platform for financial big data analytics. We briefly describe two additional tasks as follows:
- Apply NLP and machine learning approaches to further embellish the role/relationship R between filing entity X and mentioned entity Y. Of particular interest are legal proceedings and financial settlements. The embellishment may include the directionality of the role/relationship R, e.g., the filing entity X is the insurer for mentioned entity Y, or further details about the relationship, e.g., the mentioned entity Y is the insurer for a specific asset or asset class.
- Create a (labeled) (directed) (weighted) graph between filing entity X and all mentioned entities. Use that to determine the centrality of financial entity X, the exposure of filing entity X to some mentioned entity Y, etc.
Timeline
| Task announced | December 2, 2016 |
| Task details and dataset released | December 15, 2016 |
| Training data labels released | December 22, 2016 |
| Abstract for scored task / paper for non-scored-tasks | March 3, 2017 (Updated!) |
| 48 Hours to obtain test dataset and return scored results | March 21 - 24 |
| Submit Draft 2 page paper | Before March 21 |
| Return Reviews and Scores to authors | Monday April 3 |
| Camera-ready papers for all tasks | April 14, 2017 |
| DSMM Workshop | May 14, 2017 |
Submission Process
Papers should be submitted at the CMT site.
Following the submission deadline on March 15, 2017, we will compute the scores for each submission, and send you your scores, along with the distribution of scores across all participants.
We will invite a subset of participants to prepare a description of the methods used by your entry. A subset of these will be invited to speak at the SIGMOD DSMM workshop.
At the report-out workshop at SIGMOD, we will release all entries, scores, and ground truth data.