Background
The BBC Land Girls TV series is a 3 season series. Each season is 5 episodes of about 45mins each.
The TRECVID group at NIST worked with the BBC Corp. to release the dataset to the research community to work on video
understanding tasks. Unfortunately, the hosting arrangement for the dataset was not successful and the release of the video dataset
couldn't be done. We are releasing the annotations conducted by NIST, without any video data, so that the researchers interested in
working on knowledge graph understanding and natural language analysis can take advantage of them.
Web Resources
Here are some available web resources for the dataset:
wikipedia page of Land Girls (TV series)
Land Girls at BBC Online
Land Girls at IMDb
Annotations
A dedicated human annotator was hired by NIST to generate the Land Girls annotations as follows:
A static knowledge graph
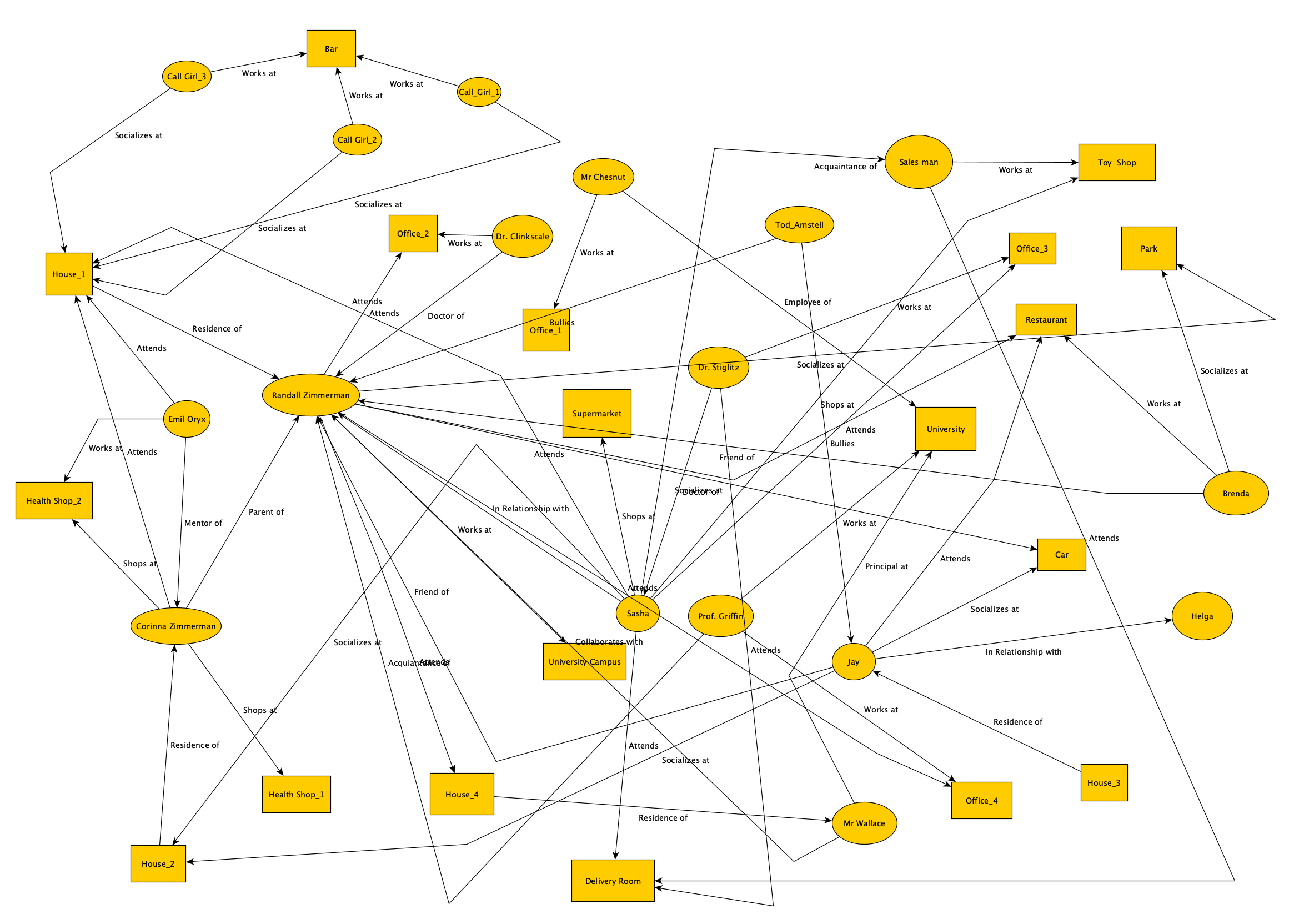
One knowledge graph was generated for each episode after watching the whole episode and extracting main entities such as key persons, locations, and relationships.
The yEd graph editor was adopted as a tool to build the static knowledge graph.
Each episode's static knowledge graph can be found under the static.kg folder. The knowledge graphs are grouped by season and files names (.xgml) end by episode ids (EP1, EP2, EP3, EP4, EP5).
Note: all xgml files can be re-saved as tgf (trivial graph format) files from the yEd editor tool which can be easier to parse and interpret.
A sample of a static movie knowledge graph
Dynamic (scene-based) knowledge graphs
Each episode scene has a corresponding json file that represents the scene knowledge graph (KG). All scene-level knowledge graphs are available in the folder dynamic.kgs
There are two main components (keys) in each json (knowledge graph) file: "nodes" and "links":
-
nodes : The nodes value is an array of objects. Where each object represents one node in the knowledge graph.
A node object consists of 3 key-value pairs:
-
a- "type" : represents the type of the node. Types available are : (Location, Person, Emotion, Interaction, Sequence, Sentiment)
-
b- "text" : representsthe label of the node. Such as location name or type, person/actor name, type of emotion, interaction or sentiment.
Please refer to the vocab.dvu.json file for a complete list of emotions, interactions, sentiments, and locations.
-
c- "key" : represents an id value to this specific node (e.g. -1, -2, -3, etc). This value is used later in the
"links" array of objects to show which nodes are linked to each other.
NOTE: Any other key-value pairs, not mentioned above, may appear but can be ignored (e.g. there may be occasions where annotators used "colors" for the node shapes).
-
links : The links value is an array of objects. Where each object represents one link (edge) between two nodes.
A link object consists of the following key-value pairs:
-
a- "from" : Uses the id (key) value of the source node as defined above under the node object "key" value.
-
b- "to" : Uses the id (key) value of the target node as defined above under the node object "key" value.
-
c- "text" : represents the value/name of the relation between the two nodes (persons).
Please refer to the vocab.dvu.json file for a complete list of relationships.
-
d- "dir" : If this is present, the default value is "2". This means that this relation or interaction is bidirectional. While if absent, means it's unidirectional.
-
e- "color" : in some cases this key-value pair may appear. You can safely skip it. It was used by some annotators to color the edge line between the two nodes.
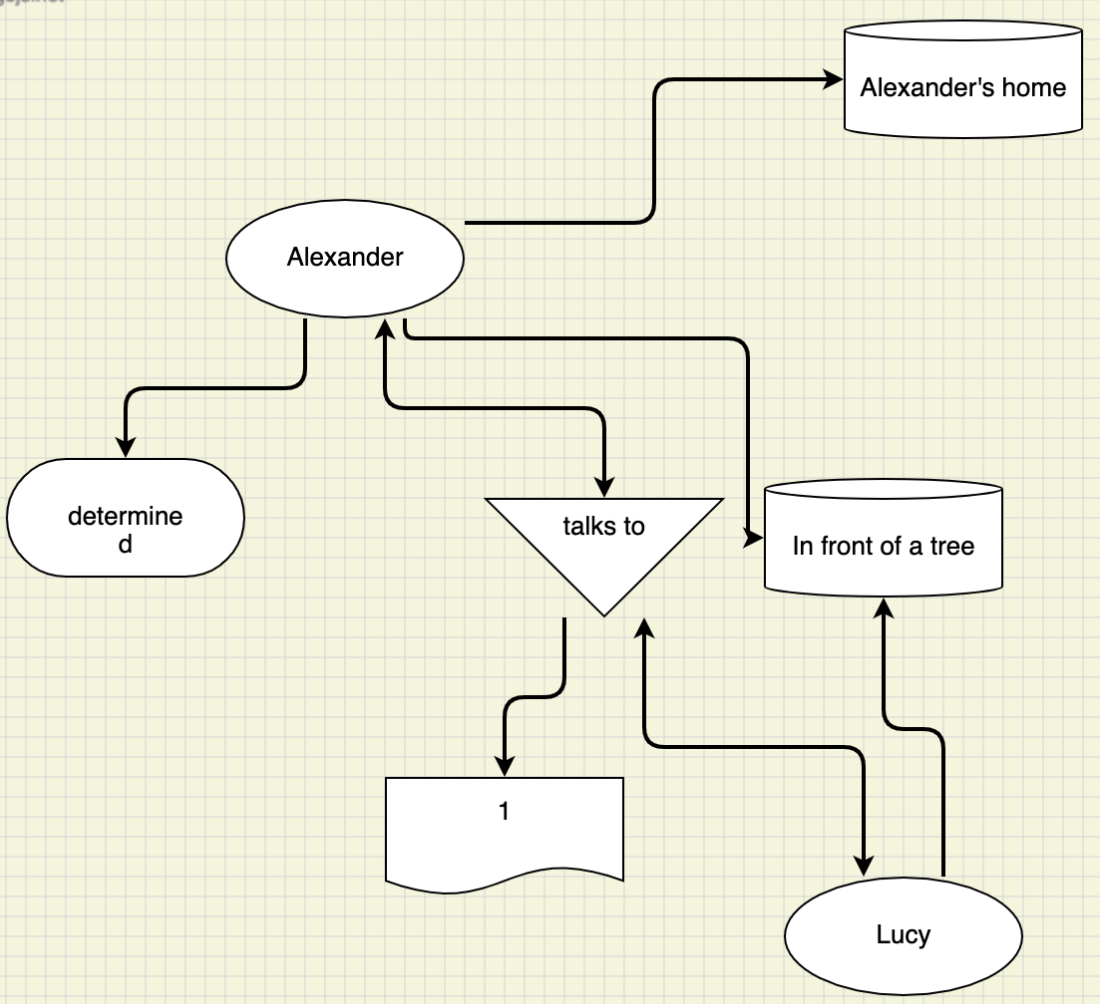
Please see below a sample scene KG outputs visually as created by annotators and the corresponding json format output:

Important annotation guidelines and notes:
- Each scene KG includes a location node to represent the location of the actors in that scene.
If a subset of actors existed in different location (e.g. phone conversation), there should be additional location node.
- A link (edge) between a person and a location means that person was in that location for the given scene.
- An emotion node was used ONLY when the annotator felt the actor's emotion was NOT neutral.
- The relationships between persons was annotated in the static whole movie KG (see the folder static.kg).
In the scene annotations, relationships are only explicitly annotated when the annotator felt the the relationship is established and became apparent.
Once annotated in a scene, it's not being repeated in following scenes, unless in some circumstances, if the relationship changed over time.
- An interaction is ONLY between persons. At least two persons need to be interacting together. The direction of the links (edges) represents the source and target
persons of the interaction. For example the "Asks" interaction may be shown as an edge between node A going into the interaction node, then another edge going from the
interaction node to node B to demonstrate that person A "Asks" person B. However, if the interaction is done by both persons, then there will be an edge going from each person
node to the interaction node.
- The Sequence node is a special type of node that is used to annotate the ORDER of the interactions in the scene. If multiple interactions happened between different actors,
the annotators use this node to annotate the sequence of interactions. The label value (value of the "text" key) of a "Sequence" node is an integer number that represents
the order of linked interaction (the value 1 represents the first interaction, 2 represents the second, etc). Please note that if a scene has only one interaction, the sequence node
annotation was optional. So, in those cases there may be no sequence nodes present in the json file for the given scene.
- One or more sentiment nodes (not linked to any other nodes in the graph) are given to each scene.
- Although every effort has been made to make sure the annotation process is consistent, there may be few occasions where annotators missed to add a sequence node when
multiple interactions happened in a scene.
- In some scenes where a person may have been in multiple locations, some annotators linked a single person node to multiple location nodes. While others created new (yet same)
person node and linked it to the new location node. In the second scenario, these two or more (same person) nodes should be combined.
- Although the ontology includes attrubutes (e.g. emotions, gender, age, etc), those were not fully utilized during annotations as applying
them appeared to be very time-consuming. Please ignore those in the scene level json files.
Ontology
The vocab.dvu.json file contains the used vocabulary in the scene annotations (json graph files).
Specifically, it has a set of:
Emotional states [used by annotators to describe unneutral actors' emotions when observed)
Interactions [used by annotators to describe the interaction type that may have happened between at least any two actors in a scene]
Relationships [used by annotators to establish a relationship between any two actors when it became apparent to them]
Sentiments [used by annotators to assign at least one sentiment to each scene]
Locations [used by annotators to describe the location type where the scene happened]
Scene language descriptions
Each scene was described in one or two english sentences. These descriptions should not substitute subtitles but should rather be understod as audio descriptions, short summaries, or video captions.
All summaries are located under the scene.summaries folder (one txt file per scene per episode).
Possible applications using the dataset
There can be many applications and usage to the provided dataset. The following are couple of examples that the authors imagine might be useful:
- Text Summarization from scene descriptions : The concatenation of all scene text descriptions acts as the text storyline
of the whole episode. In that case building a textual summary from such long story to summarize the episode can be an interesting task and application.
- Question Answering : To test the ability of a system on understanding and comprehending the episode, one can imagine a task that Given
the whole concatenation of the scenes text descriptions, a set of questions can be generated to ask about people relationships, actions,
intentions or motivations. A good system should link the events in the storyline, recognize entities, and build a relationship knowledge-base
to be able to answer these queries.
-
While the above two task ideas depend mainly on the text descriptions, a system can also take advantage of the scene KGs in addition to the text scene descritpions.
That way a more complete and hopefully rebust representation to each scene and episode can be built and used to infer answer to different types of queries.
Contact us
The authors (from the information retrieval group at NIST) can be contacted by email:
George Awad (gawad at nist.gov)
Keith Curtis (keith.curtis at nist.gov)
Shahzad Rajput (shahzad.rajput at nist.gov)
Ian Soboroff (ian.soboroff at nist.gov)